Project Details
Social Modeler is a tool for efficiently analyzing the content, intent, entities, and area of impact of large quantities of messages in news and social media.
This tool uses advanced, yet parsimonious, methods of determining the topics being talked about within a particular virtual social environment and for a particular space and time. It also determines who the major players are within the context of the discussion as well as the sentiments espoused by these players towards certain topics.
Link To Sourceforge Project SiteFeatures
We have implemented many core features of Social Modeler, but several are still in development.
Existing Features
- LDA-driven Topic Model Development
- Preprocessor with Quick Tokenizer and Streamlined Feature Selector
- Explore Interface- See Top Topics, Features, and Documents of Model
- Explore Interface- Explore Topic Time Series. Zoom in on Date Ranges of Interest.
- Configuration User Interface for Preprocessing and Model Building
- Document Import Support For File and SQL Database
Features Currently in Development
- Explore Interface- Metadata Subsetting (example metadata variables: Region, Source, Sentiment)
- Explore Interface- Entity Analysis (top entities, top topics for top entities, sentiment toward topics)
- Metadata Extraction Tools- Tools For Automating Extraction of Metadata
Methods
To acquire this information, Social Modeler uses methods from natural language processing and computational linguistics that provide the "best bang for your buck." Research has shown that to both efficiently and exhaustively process large sets of textual data is very difficult. Therefore, Social Modeler uses methods that are efficient and parsimonious but at the same provide reliable and interpretable results.
Natural Language Processing
A simple, yet effective model is used for parsing the text of interest and selecting linguistic features of relevance.
- Efficient Tokenization and Number Removal Using Regular Expressions
- A Combination of Standard and Custom Stop Word Lists
- Entity Identification Using the GATE Gazetteer
- Irrelevant Feature Removal Using Frequency Distributions and Thresholds
Topic Modeling
A popular and proven statistical method is used to extract topics from the preprocessed text source. This method is efficient and produces sensical results.
- Topic Models for Thousands of Medium-sized Documents Can Typically be Generated Within a Few Minutes
- Topics Are Easily Named Given Top Features and Documents From Social Modeler.
- Topic Prevalence Values Can Be Sliced in Many Ways, Allowing Subsetting by Time, Location, Entity, Source, Sentiment, or Other Metadata
Screenshots
(Click on thumbnail to enlarge)
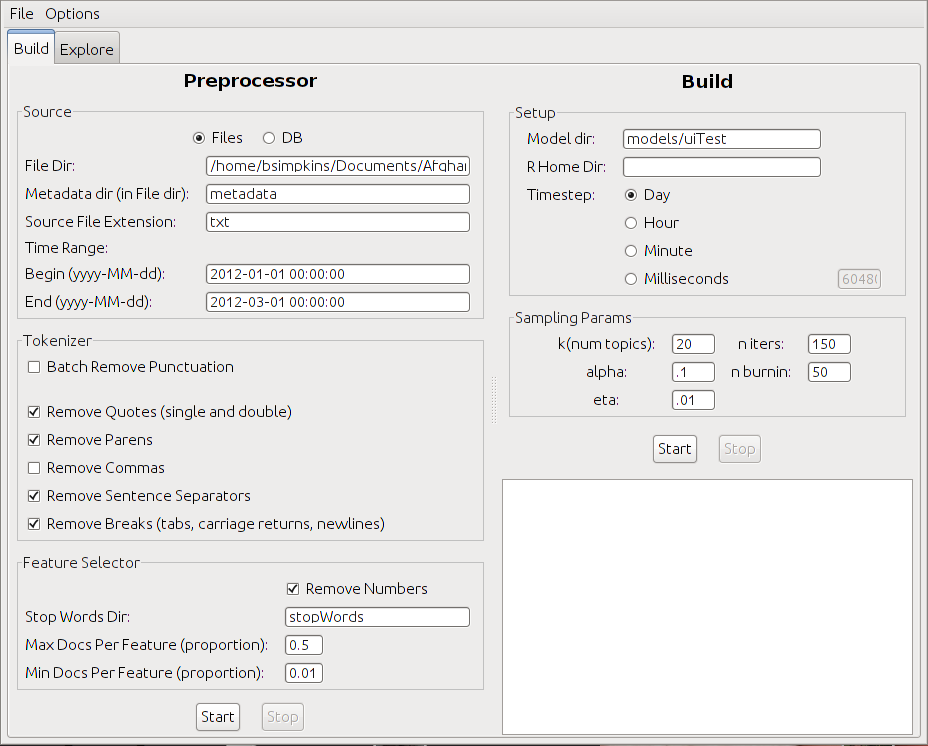
Build UI
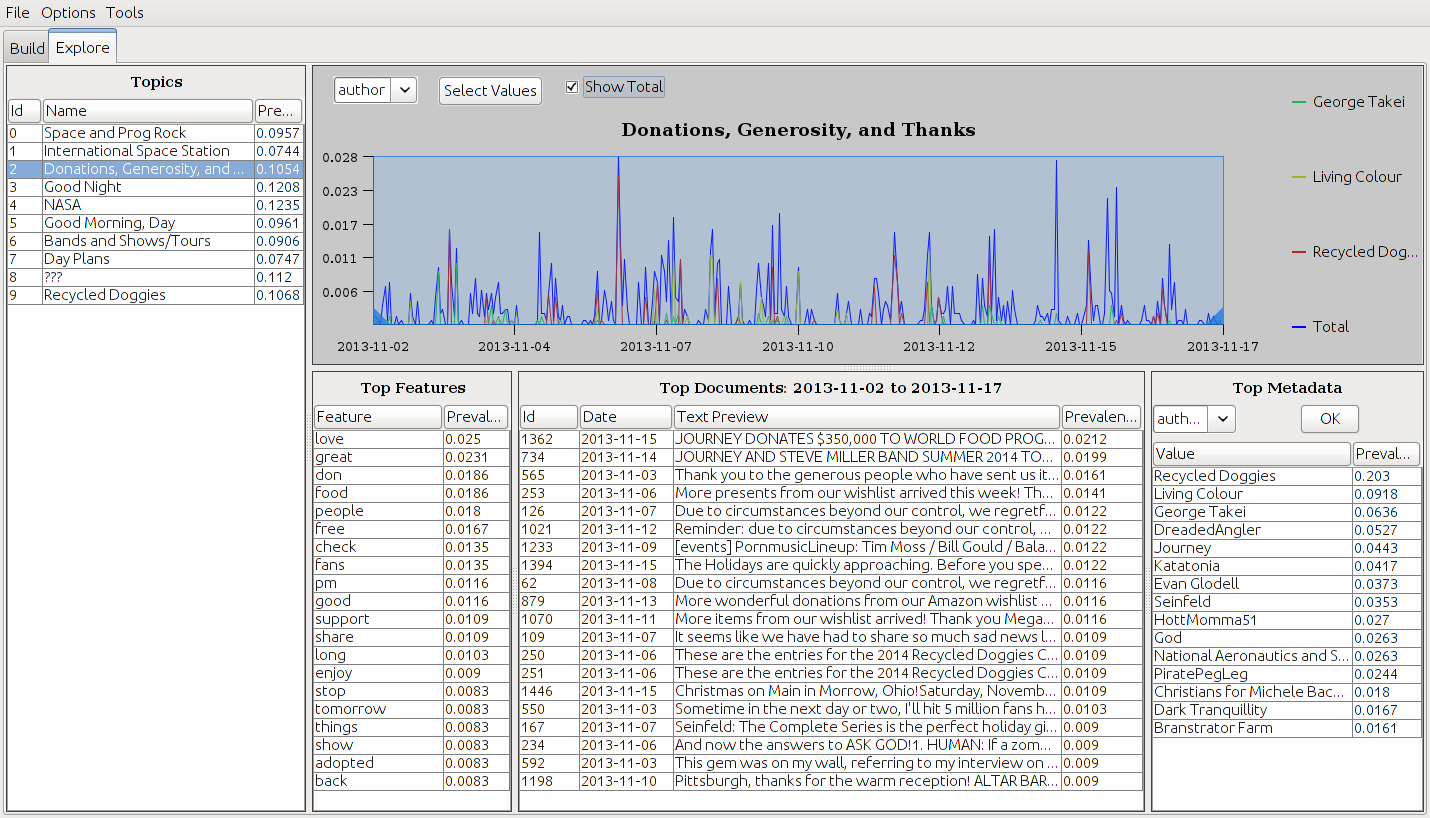
Explore UI
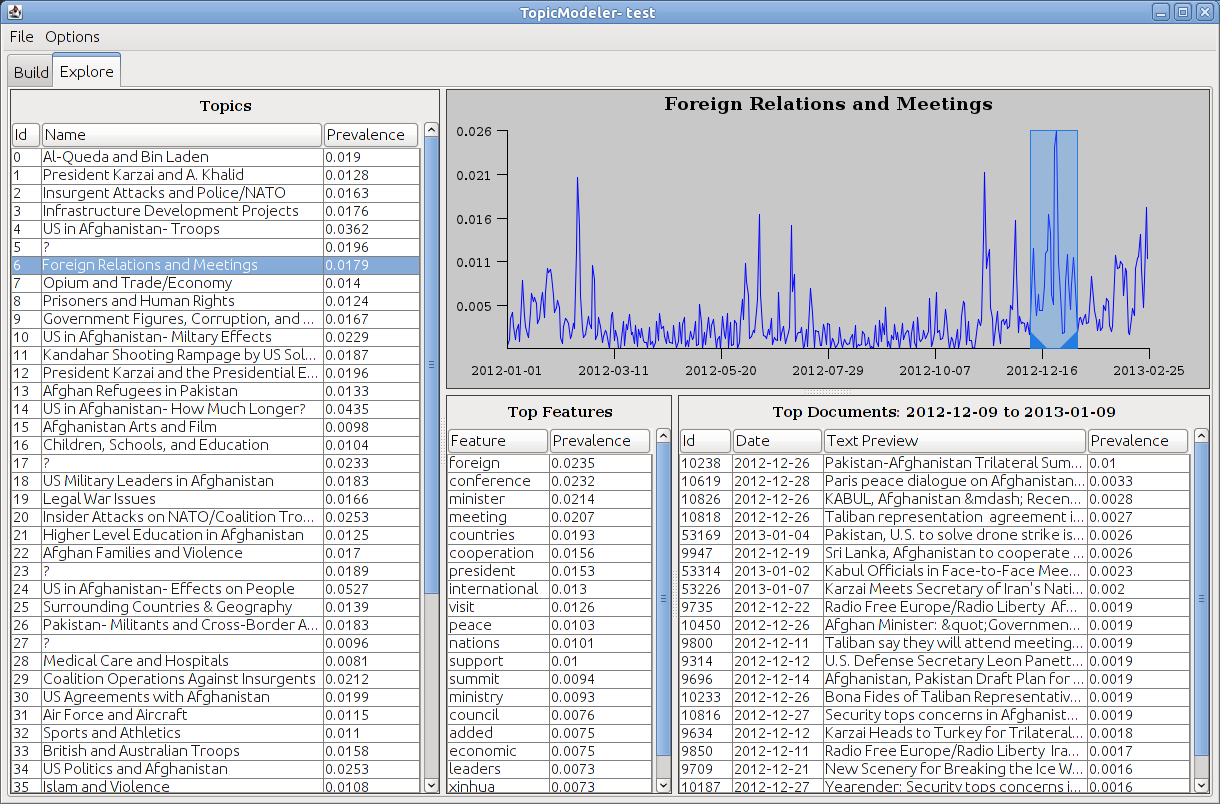
Explore UI: Date Zoom-in
Facebook Scraper
